Segmenting with Mixed Type Data - Initial data inspection and manupulation
With the new year, I started to look for new employment opportunities and even managed to land a handful of final stage interviews before it all grounded to a halt following the coronavirus pandemic. Invariably, as part of the selection process I was asked to analyse a set of data and compile a number of data driven-recommendations to present in my final meeting.
In this post I retrace the steps I took for one of the take home analysis I was tasked with and revisit clustering, one of my favourite analytic methods. Only this time the set up is a lot closer to a real-world situation in that the data I had to analyse came with a mix of categorical and numerical feature. Simply put, this could not be tackled with a bog-standard K-means algorithm as it’s based on pairwise Euclidean distances and has no direct application to categorical data.
The data
library(tidyverse)
library(readxl)
library(skimr)
library(knitr)
library(janitor)
The data represents all online acquisitions in February 2018 and their subcripion status 3 mohnths later (9th June 2018) for a Fictional News Aggregator Subscription business. It contains a number of parameters describing each account, like account creation date, campaign attributed to acquisition, payment method and length of product trial. A full description of the variables can be found in the Appendix.
I got hold of this dataset in the course of a recruitment selection process as I was asked to carry out an analysis and present results and recommendations that could helps improve their product take up in my final meeting.
Although fictitius in nature, I thought it best to further anonimise the dataset by changing names and values of most of the variables as well as removing several features that were of no use to the analysis. You can find the dataset on my GitHub profile, along with the scripts I used to carry out the analysis.
In this project I’m also testing quite a few of the adorn_ and the tabyl functions from the janitor library, a family of functions created to help expedite the initial data exploration and cleaning but also very useful to create and format summary tables.
Data loading, inspection and manupulation
As this is raw data, it needed some cleansing and rearranging. Let’s start with loading up the data and make some adjustments to the variable names.
data_raw <-
readxl::read_xlsx(
path = "../00_data/Subscription Data.xlsx",
sheet = 'Data',
trim_ws = TRUE,
col_names = TRUE,
guess_max = 2000
) %>%
# all headers to lower case
set_names(names(.) %>% str_to_lower) %>%
# shortening some names
rename_at(vars(contains("cancellation")),
funs(str_replace_all(., "cancellation", "canc"))) %>%
# swapping space with underscore in some names
rename_at(vars(contains(" ")),
funs(str_replace_all(., "[ ]", "_")))
A first glance at the data structure and it all looks in good order: all variables are in the format I would expect them to be.
data_raw %>% glimpse()
Observations: 4,853
Variables: 16
$ account_id <chr> "ID0026621", "ID0033642", "ID0036592", "ID003770...
$ created_date <dttm> 2008-11-20, 2008-11-20, 2008-11-20, 2008-11-20,...
$ country <chr> "United Kingdom", "United Kingdom", "United King...
$ status <chr> "Cancelled", "Cancelled", "Active", "Cancelled",...
$ product_group <chr> "Premium", "Standard", "Premium", "Standard", "S...
$ payment_frequency <chr> "Monthly", "Monthly", "Annual", "Monthly", "Annu...
$ campaign_code <chr> "55372", "57472", "38072", "56472", "56572", "57...
$ start_date <dttm> 2018-02-01, 2018-02-12, 2018-02-05, 2018-02-07,...
$ end_date <dttm> 2019-02-01, 2019-02-12, 2019-02-05, 2019-02-07,...
$ canc_date <dttm> 2018-02-01, 2018-03-12, NA, 2018-02-12, NA, NA,...
$ canc_reason <chr> "Amendment", "Lack of time", NA, "Failed Direct ...
$ monthly_price <dbl> 15.00, 6.99, 16.67, 0.00, 3.75, 6.99, 11.67, 6.9...
$ contract_monthly_price <dbl> 15.00, 6.99, 16.67, 6.99, 3.75, 6.99, 11.67, 6.9...
$ trial_length <chr> NA, NA, NA, "1M", NA, "1M", NA, "1M", "1M", NA, ...
$ trial_monthly_price <dbl> NA, NA, NA, 0, NA, 0, NA, 0, 0, NA, NA, NA, 0, 0...
$ payment_method <chr> "Credit Card", "Credit Card", "Direct Debit", "D...
data_raw %>% skim()
-- Data Summary ------------------------
Values
Name Piped data
Number of rows 4853
Number of columns 16
_______________________
Column type frequency:
character 9
numeric 3
POSIXct 4
________________________
Group variables None
-- Variable type: character --------------------------------------------------------
# A tibble: 9 x 8
skim_variable n_missing complete_rate min max empty n_unique whitespace
* <chr> <int> <dbl> <int> <int> <int> <int> <int>
1 account_id 0 1 9 9 0 4824 0
2 country 7 0.999 4 20 0 77 0
3 status 0 1 6 20 0 4 0
4 product_group 0 1 7 8 0 2 0
5 payment_frequency 0 1 6 10 0 3 0
6 campaign_code 0 1 5 7 0 73 0
7 canc_reason 3547 0.269 5 27 0 20 0
8 trial_length 473 0.903 2 2 0 4 0
9 payment_method 0 1 6 12 0 4 0
-- Variable type: numeric ----------------------------------------------------------
# A tibble: 3 x 11
skim_variable n_missing complete_rate mean sd p0 p25 p50
* <chr> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 monthly_price 0 1 7.34 3.79 0 6.99 6.99
2 contract_monthly_price 0 1 8.20 3.21 0 6.99 6.99
3 trial_monthly_price 474 0.902 0.00158 0.105 0 0 0
p75 p100 hist
* <dbl> <dbl> <chr>
1 6.99 26 ▁▇▁▁▁
2 6.99 26 ▁▇▁▁▁
3 0 6.94 ▇▁▁▁▁
-- Variable type: POSIXct ----------------------------------------------------------
# A tibble: 4 x 7
skim_variable n_missing complete_rate min max
* <chr> <int> <dbl> <dttm> <dttm>
1 created_date 0 1 2008-11-20 00:00:00 2018-02-28 00:00:00
2 start_date 0 1 2018-02-01 00:00:00 2018-02-28 00:00:00
3 end_date 0 1 2018-03-01 00:00:00 2019-02-28 00:00:00
4 canc_date 3549 0.269 2017-10-31 00:00:00 2019-02-21 00:00:00
median n_unique
* <dttm> <int>
1 2017-12-20 00:00:00 971
2 2018-02-14 00:00:00 28
3 2019-02-13 00:00:00 47
4 2018-04-01 00:00:00 156
Individual variables exploration
Account_id duplicates
There are 29 (58 / 2) duplicate account_id
data_raw %>%
# selecting custoomer IDs that appear more than once
group_by(account_id) %>%
count() %>%
filter(n > 1) %>%
ungroup() %>%
adorn_totals()
account_id n
ID0677A2A 2
ID0741332 2
ID1391299 2
ID13A4A40 2
ID13A9243 2
ID1424249 2
ID1512645 2
ID1524272 2
ID155207A 2
ID193604A 2
ID1A1923A 2
ID1A32751 2
ID2761201 2
ID35A3764 2
ID4233600 2
ID4492593 2
ID4A21A21 2
ID4AA7757 2
ID5050A03 2
ID5245472 2
ID5672544 2
ID5679641 2
ID5709A95 2
ID5736607 2
ID5770621 2
ID5774546 2
ID5775354 2
ID57753A9 2
ID5A03505 2
Total 58
It looks like the large majority of duplicate customer ID are linked to an Amendment on their account.
data_raw %>%
group_by(account_id) %>%
count() %>%
filter(n > 1) %>%
ungroup() %>%
# appending all data back in
left_join(data_raw) %>%
# select some columns for a closer look
select(account_id, canc_reason) %>%
arrange(canc_reason)
account_id canc_reason
<chr> <chr>
ID0741332 Amendment
ID13A4A40 Amendment
ID155207A Amendment
ID193604A Amendment
ID1A1923A Amendment
ID1A32751 Amendment
ID2761201 Amendment
ID35A3764 Amendment
ID4233600 Amendment
ID4492593 Amendment
ID4A21A21 Amendment
ID4AA7757 Amendment
ID4AA7757 Amendment
ID5050A03 Amendment
ID5245472 Amendment
ID5679641 Amendment
ID5709A95 Amendment
ID5774546 Amendment
ID5775354 Amendment
ID57753A9 Amendment
ID5A03505 Amendment
ID5709A95 Competitor
ID155207A Failed Credit Card Payment
ID1A32751 Failed Credit Card Payment
ID13A4A40 Lack of time
ID5774546 Lack of time
ID1424249 Not known
ID5736607 Not known
ID0677A2A Product switch
ID1391299 Product switch
ID5672544 Product switch
ID5770621 Product switch
ID13A9243 Unknown
ID1512645 Unknown
ID1524272 Unknown
ID0677A2A NA
ID0741332 NA
ID1391299 NA
ID13A9243 NA
ID1424249 NA
ID1512645 NA
ID1524272 NA
ID193604A NA
ID1A1923A NA
ID2761201 NA
ID35A3764 NA
ID4233600 NA
ID4492593 NA
ID4A21A21 NA
ID5050A03 NA
ID5245472 NA
ID5672544 NA
ID5679641 NA
ID5736607 NA
ID5770621 NA
ID5775354 NA
ID57753A9 NA
ID5A03505 NA
Given the very small number of duplicates compared to the total, I’m simply removing the duplicates.
data_clean <-
data_raw %>%
group_by(account_id) %>%
count() %>%
filter(n == 1) %>%
ungroup() %>%
# appending all data back in
left_join(data_raw) %>%
select(-n)
Country
Overwhelming majority of subscriptions are UK based
data_raw %>%
group_by(country) %>%
count() %>%
ungroup() %>%
arrange(desc(n)) %>%
ungroup() %>%
mutate(country = country %>% as_factor()) %>%
filter(n > 7) %>%
ggplot(aes(x = country, y = n)) +
geom_col(fill = "#E69F00", colour = "red") +
theme_minimal() +
labs(title = 'Number of subscriptions by acquisition country',
caption = '',
x = 'Country of Residence',
y = 'Number of Subscribers') +
theme(plot.title = element_text(hjust = 0.5),
axis.text.x = element_text(angle = 45, hjust = 1, size = 8))
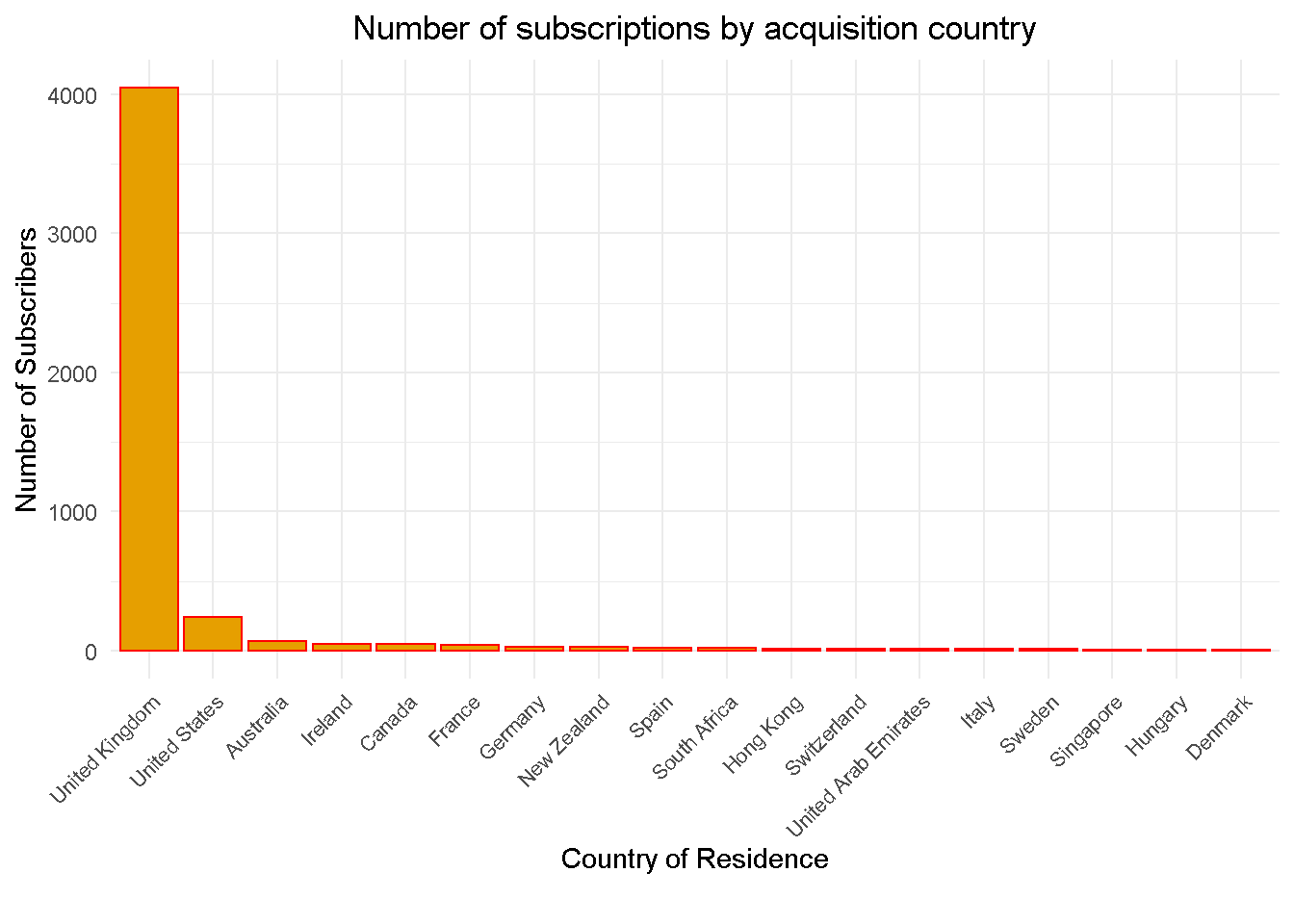
Status
Majority of accounts are either Active or Cancelled
data_raw %>%
group_by(status) %>%
count() %>%
ungroup() %>%
janitor::adorn_totals()
status n
Active 3542
Cancelled 1257
Lapsed 7
Pending Cancellation 47
Total 4853
I’m rolling Lapsed and Pending Cancellation into Cancelled
data_clean <-
data_clean %>%
mutate(status =
case_when(status == 'Lapsed' ~ 'Cancelled',
status == 'Pending Cancellation' ~ 'Cancelled',
TRUE ~ status)
)
Product group
All looks OK here
# no NAs
data_raw %>%
group_by(product_group) %>%
count() %>%
ungroup() %>%
janitor::adorn_totals()
product_group n
Premium 666
Standard 4187
Total 4853
Payment Frequency
Under payment frequency there are only a handful of Fixed Term
# no NAs
data_raw %>%
group_by(payment_frequency) %>%
count() %>%
ungroup() %>%
janitor::adorn_totals()
payment_frequency n
Annual 318
Fixed Term 11
Monthly 4524
Total 4853
I’m dropping Fixed Term
data_clean <-
data_clean %>%
filter(payment_frequency != 'Fixed Term')
Campaign
Top three campaigns account for over 72% of total acquisitions in February 2018
# no NAs
data_raw %>%
group_by(campaign_code) %>%
count() %>%
ungroup() %>%
arrange(desc(n)) %>%
ungroup() %>%
mutate(campaign_code = campaign_code %>% as_factor()) %>%
filter(n > 3) %>%
ggplot(aes(x = campaign_code, y = n)) +
geom_col(fill = "steelblue", colour = "blue") +
theme_minimal() +
labs(title = 'Number of subscriptions by acquisition campaign',
caption = '',
x = 'Campaign Code',
y = 'Number of Subscribers') +
theme(plot.title = element_text(hjust = 0.5),
axis.text.x = element_text(angle = 45, hjust = 1, size = 8))
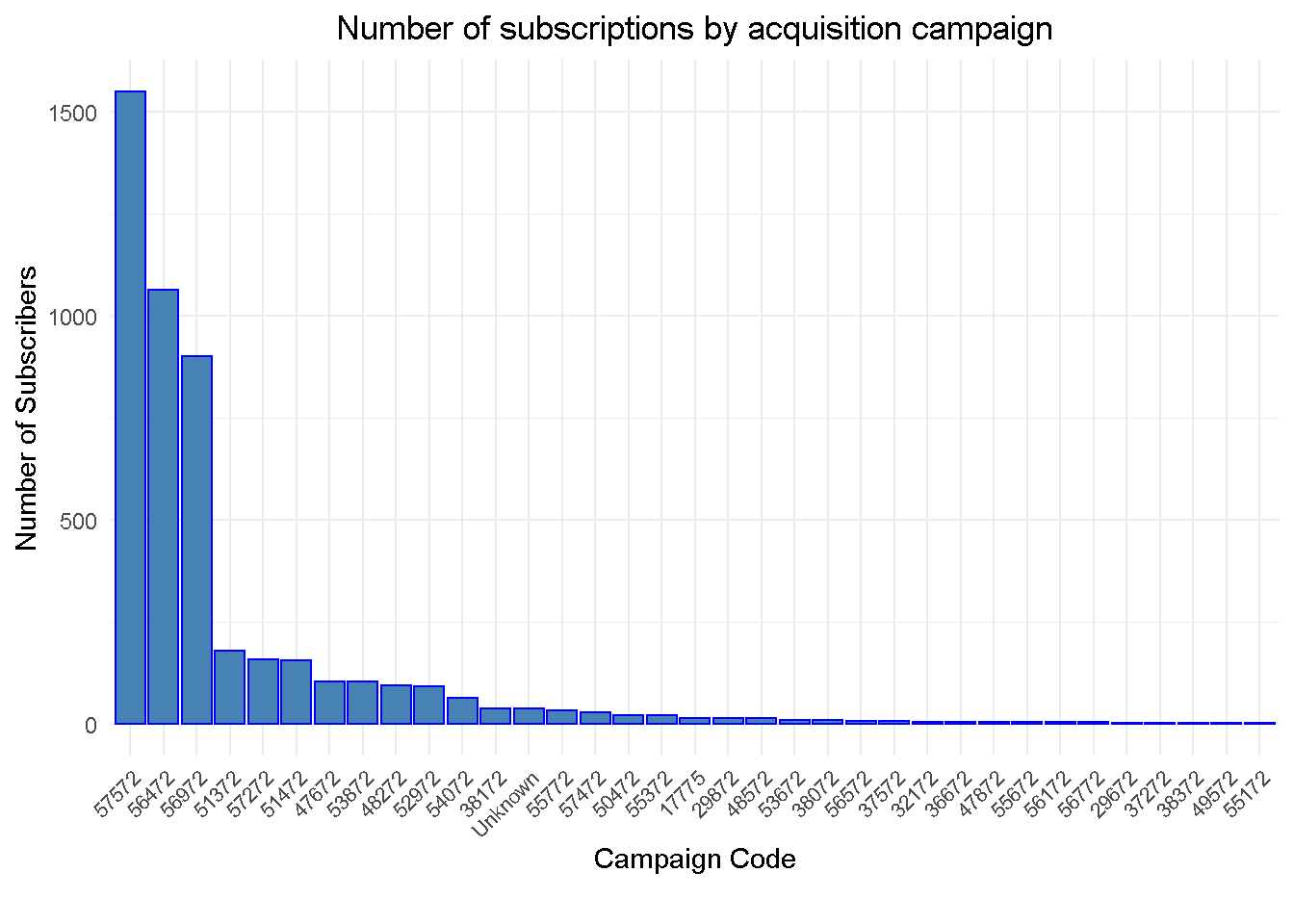
Dropping unknown campaign code
data_clean <-
data_clean %>%
filter(campaign_code != 'Unknown')
Trial end date
trial_monthly_price price should be zero for all
data_raw %>%
select(contains('trial'), monthly_price) %>%
# filter(!(trial_end_date)) %>%
arrange(desc(trial_length)) %>%
head() %>%
kable(align = 'c')
trial_length trial_monthly_price monthly_price
6M 6.94 6.94
6M 0.00 0.00
6M 0.00 0.00
6M 0.00 0.00
6M 0.00 0.00
6M 0.00 0.00
Amending trial_monthly_price to zero and the 6.94 monthly_price to 6.99
data_clean <-
data_clean %>%
mutate(trial_monthly_price =
case_when(trial_monthly_price == 6.94 ~ 0,
TRUE ~ trial_monthly_price),
monthly_price =
case_when(monthly_price == 6.94 ~ 6.99,
TRUE ~ monthly_price)
)
Cancellation date / reason
there’s too much noise in the cancellation reasons, which needs simplifying to get a clear read
data_raw %>%
group_by(status, canc_reason) %>%
count() %>%
ungroup() %>%
arrange(status, n) %>%
janitor::adorn_totals()
status canc_reason n
Active Unknown 16
Active <NA> 3526
Cancelled Apple news 1
Cancelled Download 1
Cancelled App performance 2
Cancelled Political 4
Cancelled No compatible devices 6
Cancelled Look and feel 10
Cancelled Product switch 16
Cancelled Competitor 17
Cancelled Editorial 18
Cancelled Duplicate subscription 19
Cancelled Lack of content 21
Cancelled <NA> 21
Cancelled Unknown 30
Cancelled Functionality 40
Cancelled Amendment 74
Cancelled Failed Direct Debit Payment 84
Cancelled Price 100
Cancelled Failed PayPal Payment 144
Cancelled Not known 190
Cancelled Lack of time 228
Cancelled Failed Credit Card Payment 231
Lapsed Unknown 7
Pending Cancellation Competitor 1
Pending Cancellation Functionality 1
Pending Cancellation Lack of content 1
Pending Cancellation Price 1
Pending Cancellation Unknown 1
Pending Cancellation Failed Direct Debit Payment 2
Pending Cancellation Failed Credit Card Payment 10
Pending Cancellation Not known 14
Pending Cancellation Lack of time 16
Total - 4853
Grouping up some of the reason for cancelling and dealing with the NAs
data_clean <-
data_clean %>%
mutate(
canc_reason =
case_when(
status == 'Active' & canc_reason == 'Unknown' ~ '-',
# setting all NAs to zero as they're easier to deal with
is.na(canc_reason) ~ '-',
canc_reason == 'App performance' |
canc_reason == 'No compatible devices' |
canc_reason == 'Look and feel' |
canc_reason == 'Functionality' |
canc_reason == 'Download' ~ 'UX Related',
canc_reason == 'Failed Credit Card Payment' |
canc_reason == 'Failed PayPal Payment' |
canc_reason == 'Failed Direct Debit Payment' ~ 'Failed Payment',
canc_reason == 'Political' |
canc_reason == 'Editorial' |
canc_reason == 'Lack of content' ~ 'Editorial',
canc_reason == 'Competitor' |
canc_reason == 'Apple news' ~ 'Competitor',
canc_reason == 'Product switch' |
canc_reason == 'Amendment' |
canc_reason == 'Duplicate subscription' ~ 'Other',
canc_reason == 'Not known' |
canc_reason == 'Unknown' ~ '-',
TRUE ~ canc_reason)
)
Trial length
Majority of subscriptions go for 1M (one month) trial. I’ve triangulated dates with trial length and they all check out. NAs represent subscribers already enrolled so no trial for them
data_raw %>%
group_by(trial_length) %>%
count() %>%
ungroup() %>%
janitor::adorn_totals()
trial_length n
1M 4277
2M 1
3M 95
6M 7
<NA> 473
Total 4853
Price
data_clean %>%
filter(country == 'United Kingdom') %>%
group_by(
monthly_price,
contract_monthly_price
) %>%
count() %>%
ungroup() %>%
arrange(desc(n)) %>%
janitor::adorn_totals()
monthly_price contract_monthly_price n
6.99 6.99 2904
15 15.00 363
0 6.99 273
8.33 8.33 132
0 15.00 52
9.65 9.65 48
0 9.65 21
3.75 3.75 21
20.83 20.83 21
26 26.00 19
12.5 12.50 18
0 0.00 17
16.67 16.67 14
0 26.00 13
11.67 11.67 9
1 6.99 5
6.25 6.25 4
6.67 6.67 3
19.5 19.50 3
17.33 17.33 2
21.67 21.67 2
1 15.00 1
5 5.00 1
5 15.00 1
6.5 15.00 1
6.99 9.65 1
7.33 11.67 1
7.5 7.50 1
10.83 10.83 1
13.33 13.33 1
15 26.00 1
15.17 15.17 1
18.33 18.33 1
20 20.00 1
Total 449.92 3957
Where monthly_price is zero they’ve all cancelled. I believe it coincides with old customers who cancelled on Feb-18
data_clean %>%
filter(trial_length == '1M') %>% # 4233 are 1M subscriptions or 90% of total
group_by(
product_group,
trial_monthly_price, # all zero
monthly_price,
contract_monthly_price) %>%
count() %>%
ungroup() %>%
janitor::adorn_totals()
product_group trial_monthly_price monthly_price contract_monthly_price n
Premium 0 0.00 15.00 54
Premium 0 5.00 15.00 1
Premium 0 6.50 15.00 1
Premium 0 15.00 15.00 343
Standard 0 0.00 6.99 308
Standard 0 0.00 9.65 33
Standard 0 1.00 6.99 6
Standard 0 6.99 6.99 3392
Standard 0 9.65 9.65 95
Total 0 44.14 100.27 4233
Payment method
A handful of Unknown are to be found in payment_method
data_raw %>%
group_by(payment_method) %>%
count() %>%
ungroup() %>%
adorn_totals()
payment_method n
Credit Card 2966
Direct Debit 632
PayPal 1244
Unknown 11
Total 4853
Dropping unknown
data_clean <-
data_clean %>%
filter(payment_method != 'Unknown')
A final look at the cleansed data: I’m happy with everything here!
data_clean %>%
skim()
-- Data Summary ------------------------
Values
Name Piped data
Number of rows 4749
Number of columns 16
_______________________
Column type frequency:
character 9
numeric 3
POSIXct 4
________________________
Group variables None
-- Variable type: character ------------------------------------------------------
# A tibble: 9 x 8
skim_variable n_missing complete_rate min max empty n_unique whitespace
* <chr> <int> <dbl> <int> <int> <int> <int> <int>
1 account_id 0 1 9 9 0 4749 0
2 country 1 1.00 4 20 0 77 0
3 status 0 1 6 9 0 2 0
4 product_group 0 1 7 8 0 2 0
5 payment_frequency 0 1 6 7 0 2 0
6 campaign_code 0 1 5 5 0 70 0
7 canc_reason 0 1 1 14 0 8 0
8 trial_length 413 0.913 2 2 0 4 0
9 payment_method 0 1 6 12 0 3 0
-- Variable type: numeric --------------------------------------------------------
# A tibble: 3 x 11
skim_variable n_missing complete_rate mean sd p0 p25 p50
* <chr> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 monthly_price 0 1 7.34 3.69 0 6.99 6.99
2 contract_monthly_price 0 1 8.17 3.12 0 6.99 6.99
3 trial_monthly_price 413 0.913 0 0 0 0 0
p75 p100 hist
* <dbl> <dbl> <chr>
1 6.99 26 ▁▇▁▁▁
2 6.99 26 ▁▇▁▁▁
3 0 0 ▁▁▇▁▁
-- Variable type: POSIXct --------------------------------------------------------
# A tibble: 4 x 7
skim_variable n_missing complete_rate min max
* <chr> <int> <dbl> <dttm> <dttm>
1 created_date 0 1 2008-11-20 00:00:00 2018-02-28 00:00:00
2 start_date 0 1 2018-02-01 00:00:00 2018-02-28 00:00:00
3 end_date 0 1 2018-03-04 00:00:00 2019-02-28 00:00:00
4 canc_date 3511 0.261 2017-10-31 00:00:00 2019-02-19 00:00:00
median n_unique
* <dttm> <int>
1 2017-12-25 00:00:00 958
2 2018-02-13 00:00:00 28
3 2019-02-13 00:00:00 29
4 2018-04-04 00:00:00 153
Saving data_clean
# Saving clensed data for analysis phase
saveRDS(data_clean, "../00_data/data_clean.rds")
Code Repository
The full R code and all relevant files can be found on my GitHub profile @ K Medoid Clustering
References
For the article that inspired my foray into K-medois clustering see this excellent TDS post by Thomas Filaire: Clustering on mixed type data
For a tidy and fully-featured approach to counting things, see the tabyls Function Vignette
Appendix
Table 1 – Variable Definitions
| Attribute | Description |
|---|---|
| Account ID | Unique account ID |
| Created Date | Date of original account creation |
| Country | Country of account holder |
| Status | Current status - active/inactive |
| Product Group | Product type |
| Payment Frequency | Most subscriptions are a 1 year contract term - payable annually or monthly |
| Campaign Code | Unique identifier for campaign attributed to acquisition |
| Start Date | Start date of the trial |
| End Date | Scheduled end of term |
| Cancellation Date | Date of instruction to cancel |
| Cancellation Reason | Reason given for cancellation |
| Monthly Price | Current monthly price of subscription |
| Contract Monthly Price | Price after promo period |
| Trial Length | Length of trial |
| Trial Monthly Price | Price during trial |
| Payment Method | Payment method |